
HPC 向けの新サービス AWS Parallel Computing Service が登場しました
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
HPC ワークロード向けの新サービス AWS Parallel Computing Service(AWS PCS)が登場しました。AWS Batch ほどのフルマネージドサービスではなく、AWS ParallelCluster ほどセルフサービスでもない、AWS ParallelCluster よりのマネージドな HPC サービスです。
なにが嬉しいのか
平たく言えば AWS ParallelCluster の一部をマネージドサービス化したようなサービスです。
- 可用性の向上
- AWS ParallelCluster の単一障害点だったジョブスケジューラがマネージドサービスとなり、可用性が向上しました
- 運用負荷の軽減
- AWS ParalleCluster と比べると管理リソースが減りました
- ユーザーは計算環境の設定と実行処理の指示に集中できます
HPC ワークロード向けの AWS サービス一覧
AWS ParallelCluster と AWS Batch の間に位置するマネージドサービスです。だいぶ AWS ParallelCluster よりではあります。

AWS ParallelCluster を基準にどのような進化を遂げたのか確認すると AWS PCS のことがわかりやすいです。AWS ParallelCluster の構成を理解するには、まずスーパーコンピューター(スパコン)の基本構成を把握することが近道です。なので、AWS PCS の話に入る前に手短に HPC のお話をします。
スパコンの基本的な構成と利用方法
スパコンの基本的な利用方法はこのような感じです。
- ユーザーがジョブスクリプトを作成
- ログインノードからジョブスケジューラにジョブをサブミット
- ジョブスケジューラが実行先の計算ノードを決定
- 計算ノードでジョブを実行
- 計算ノードで実行した結果をユーザーが確認
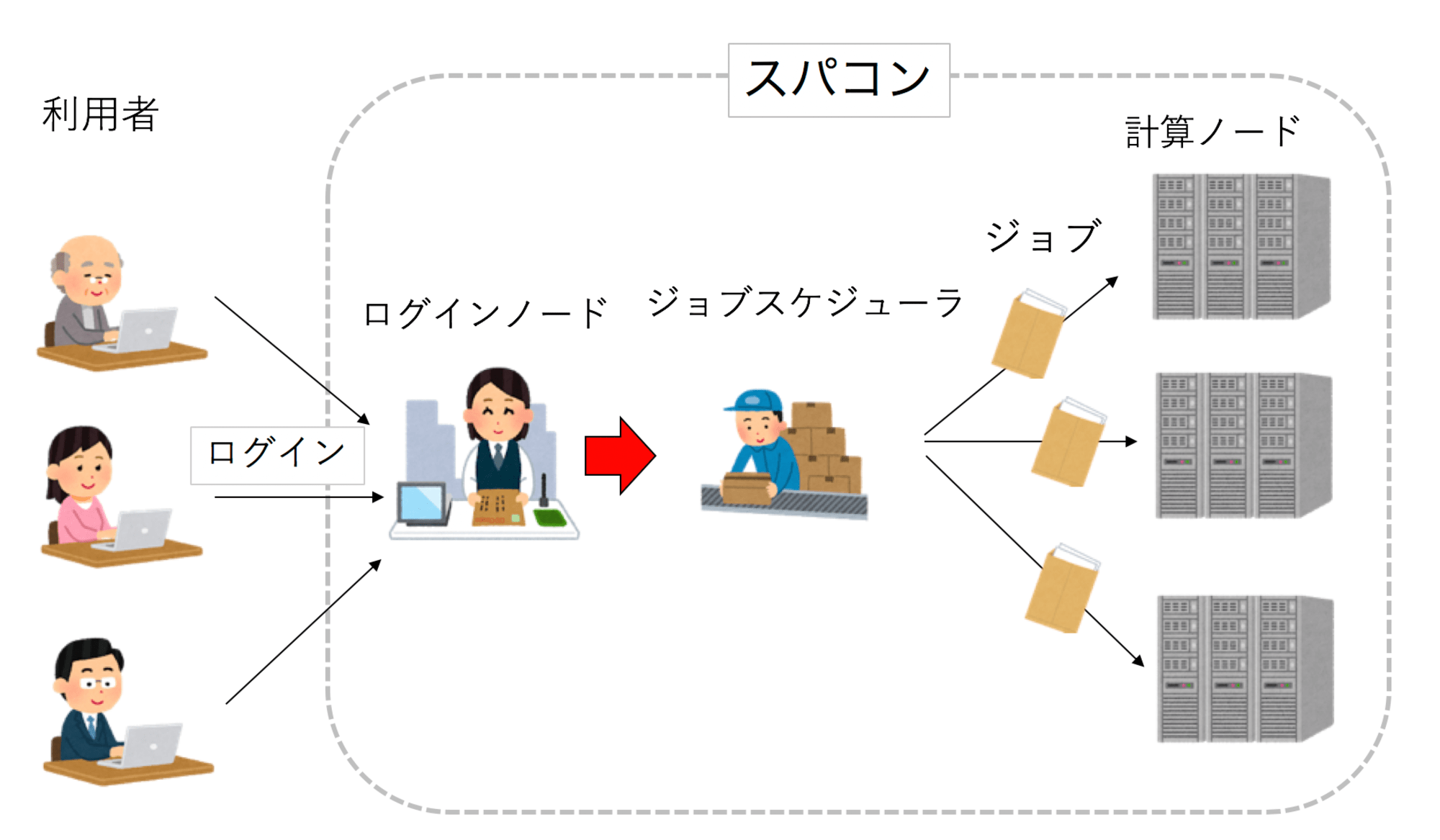
出典: Day 2 : スパコンの使い方 © 一週間でなれる!スパコンプログラマ (CC-BY-4.0)
詳しい説明については、上の図の出典元である大変わかりやすい説明の一週間でなれる!スパコンプログラマから引用します。
ローカルPCは自分しか使わないので、好きな時に好きなプログラムを実行して良い。しかし、スパコンは大勢で共有する計算資源であり、各自が好き勝手にプログラムを実行したら大変なことになるため、なんらかの交通整理が必要となる。その交通整理を行うのが「ジョブスケジューラ」である。スパコンでは、プログラムは「ジョブ」という単位で実行される。ユーザはまず、「ジョブスクリプト」と呼ばれるシェルスクリプトを用意する。これは、自分のプログラムの実行手順を記した手紙のようなものである。次にユーザは、ログインノードからジョブスケジューラにジョブの実行を依頼する(封筒をポストに入れるイメージ)。こうしてジョブは実行待ちリストに入る。ジョブスケジューラは実行待ちのジョブのうち、これまでの利用実績や、要求ノード数、実行時間などを見て、次にどのジョブがどこで実行されるべきか決定する。
引用: Day 2 : スパコンの使い方
スパコンと AWS ParallelCluster を比較
EC2 をうまいことスパコンとして機能させるためのフレームワークが AWS ParallelCluster です。以下の機能が備わっています。
- ジョブスケジューラが設定済みのヘッドノード(EC2)
- 計算するときに自動的に起動・終了するコンピュートノード(EC2)
- ヘッドノードと、コンピュートノードの組み合わせをクラスターと呼びます
AWS ParallelCluster の基本構成をスパコンの構成に当てはめると以下になります。
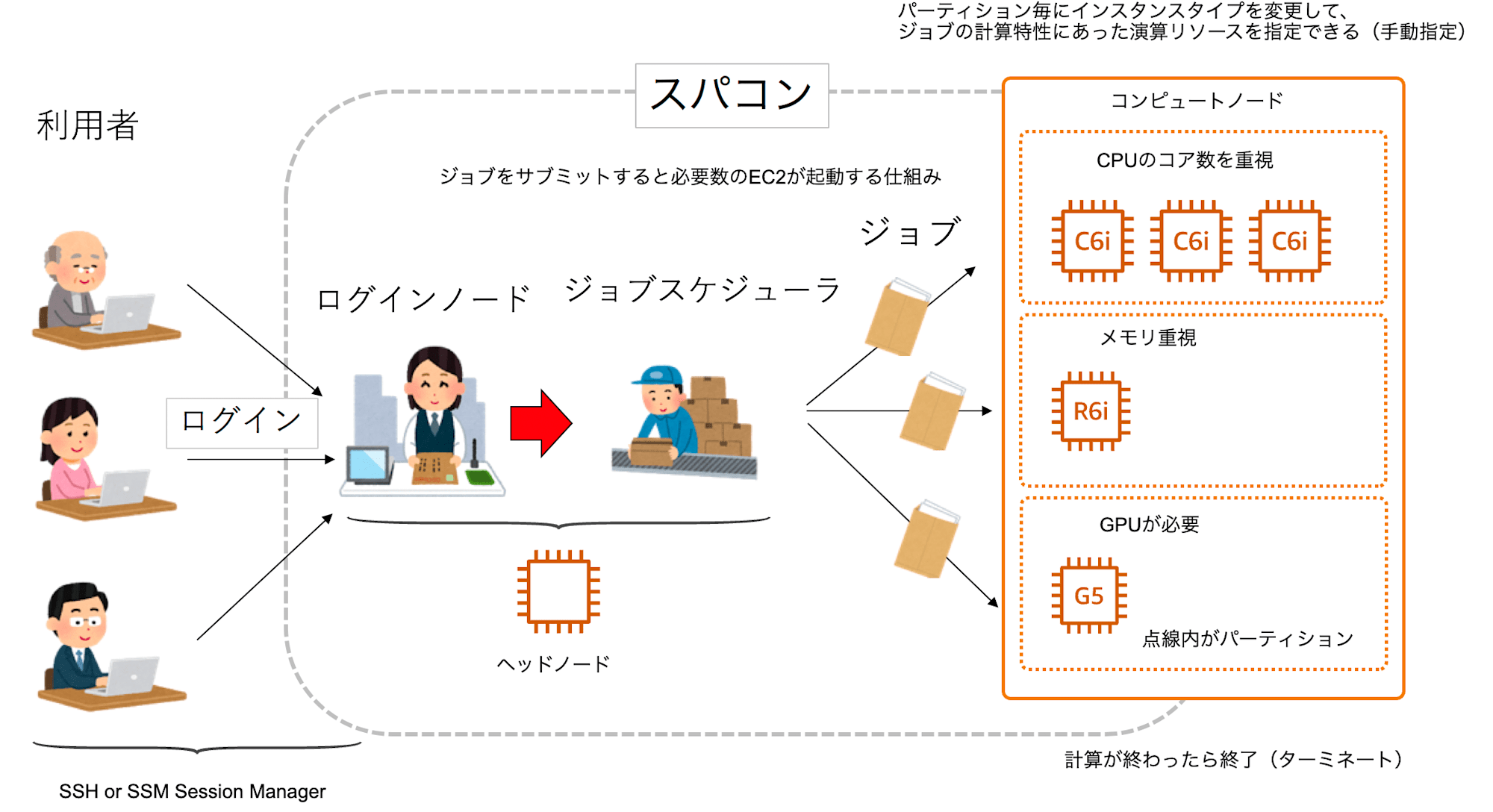
出典: Day 2 : スパコンの使い方 © 一週間でなれる!スパコンプログラマ (CC-BY-4.0)
変更点: AWS ParallelCluster の構成を元の図に埋め込み
通常は EFS や FSx for Lustre + S3 などのストレージサービスと連携して利用することになります。大容量の共有ストレージが欲しくなりますからね。
AWS ParallelCluster と AWS PCS を比較
AWS PCS は、AWS ParallelCluster の基本構成を踏襲しつつ、主に以下の改善が加わってます。
- ジョブスケジューラのマネージドサービス化
- AWS ParallelCluster:ヘッドノードがログインノードとジョブスケジューラを兼任
- AWS PCS:ジョブスケジューラがマネージドサービスとして独立して別管理
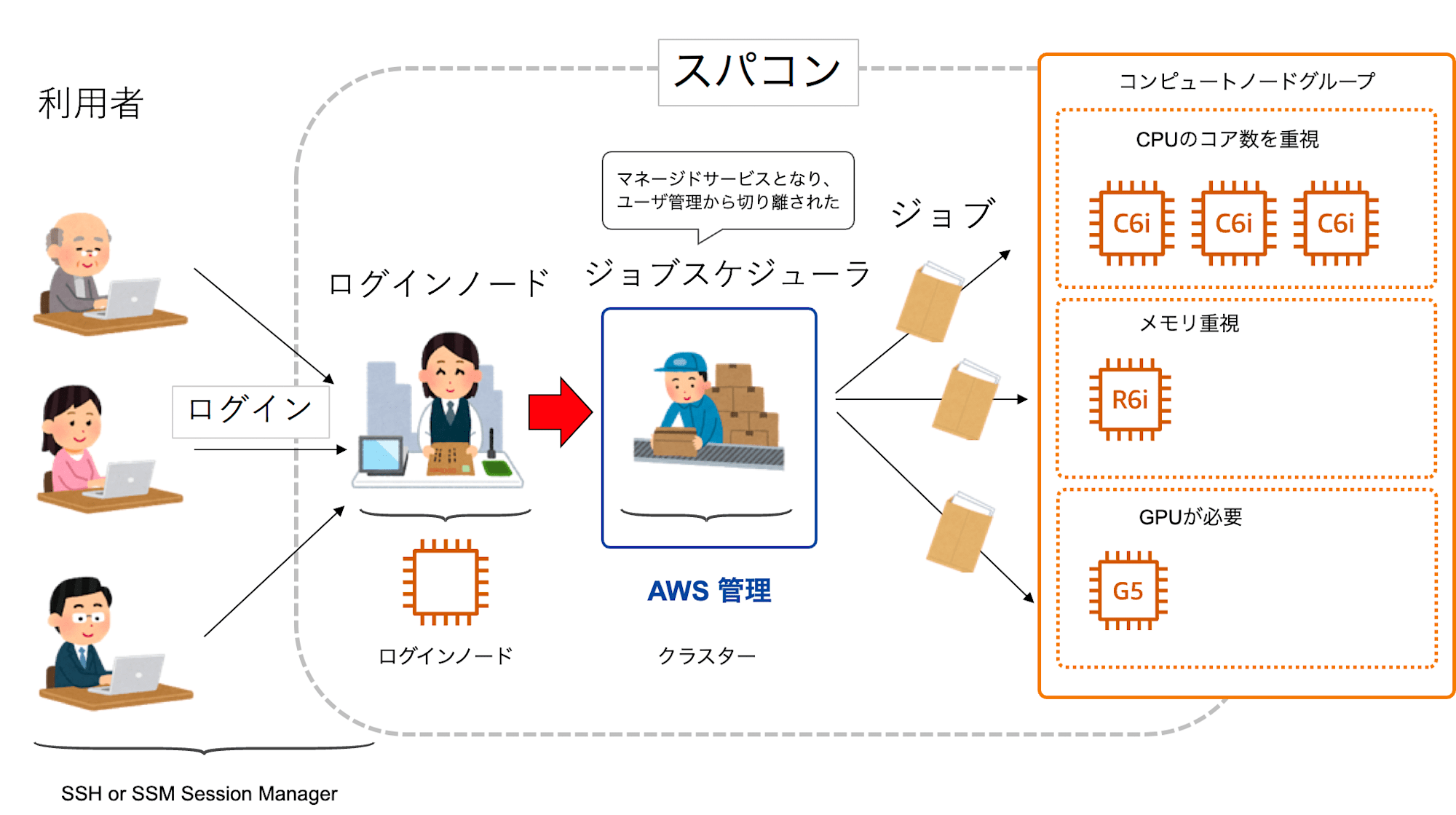
出典: Day 2 : スパコンの使い方 © 一週間でなれる!スパコンプログラマ (CC-BY-4.0)
変更点: AWS PCS の構成を元の図に埋め込み
- 可用性の向上
- AWS ParallelCluster:ヘッドノードが単一障害点
- AWS PCS:AWS 管理のジョブスケジューラになり高い可用性を実現
ちなみに AWS PCS ではジョブスケジューラは 「クラスター」という名前のリソース名で管理され、ジョブスケジューラ自体のことは「PCS コントローラー」と呼ばれていました。
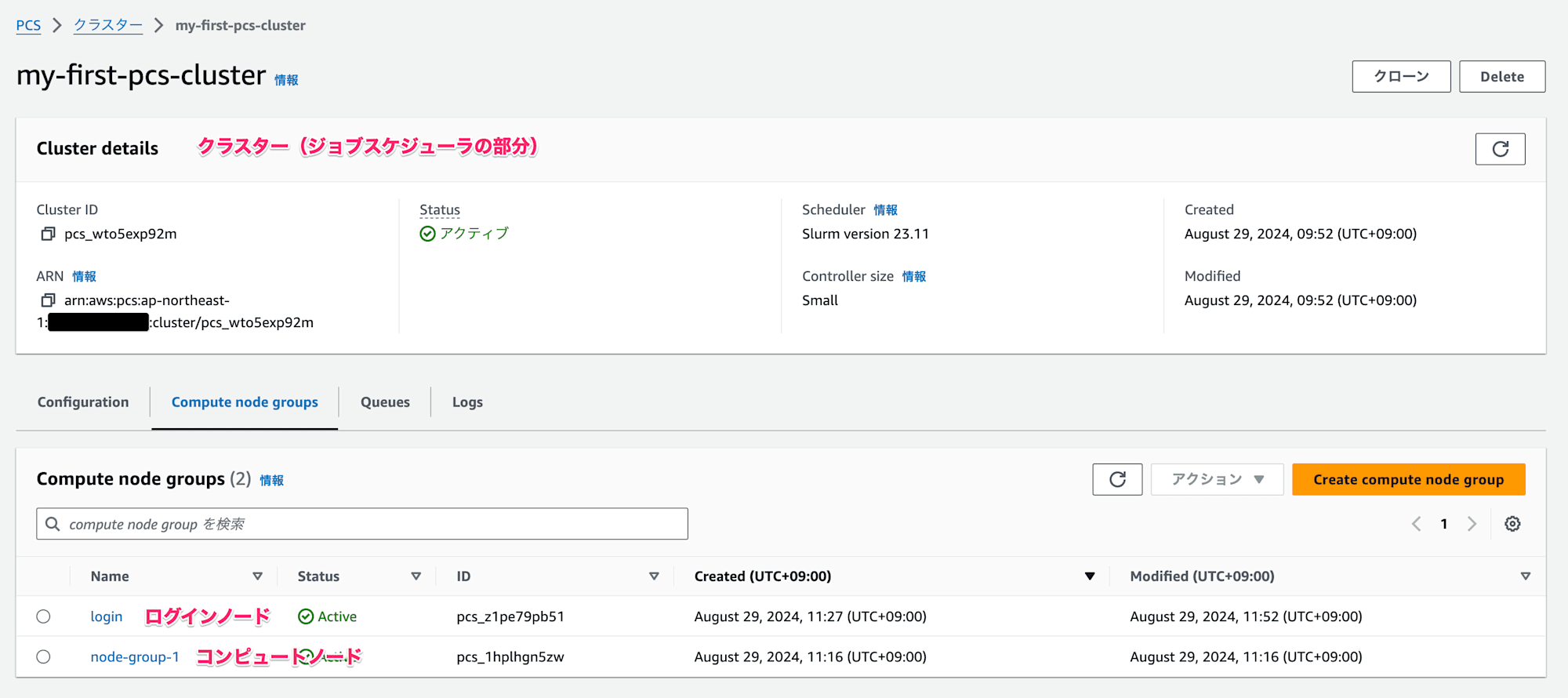
AWS PCS は可用性が高く管理しやすい HPC 環境を提供してくれます。
AWS PCS の気になるところ
クラスター構築しながら知り得たことを書いておきます。
ジョブスケジューラはなんですか?
ジョブスケジューラは Slurm のみ対応しています。
コンピュートノード(ホスト)のカスタマイズはできますか?
起動テンプレートで設定を入れ込む方式です。例えば EFS のマウント設定などは起動テンプレートから指定します。
AWS ParallelCluster とは異なり独自の実装ではなく、AWS が用意してあるサービスを利用するようなので学習コストは下がりそうです。
独自の AMI はコンピュートノードで利用可能ですか?
利用できます。なんなら本番利用は独自の AMI 利用が推奨でした。起動テンプレートから設定が難しいものは AMI に焼き込んでおく方法もとれます。
If you are using AWS PCS in production, we recommend you build your own AMIs.
引用: Amazon Machine Images (AMIs) for AWS PCS - AWS PCS
コンテナ起動して計算できますか?
コンテナで計算する HPC サービスと言えば AWS Batch ですが、AWS ParallelCluster でも可能でした。起動テンプレートか、独自の AMI に Docker ないし、Apptainer の設定入れ込めばコンテナ上での計算処理はできそうです。(未検証)
AWS PCS の使い方
AWS PCS の利用方法は、従来のスパコンや AWS ParallelCluster とほぼ同じでした。AWS PCS でのクラスター構築方法は後日紹介します。
- ログインノードへの接続
- EC2 インスタンスとして起動しているので接続するだけ
- セッションマネージャーまたは SSH を使用
- Slurm コマンドの利用可能
ログイン後、以下のような Slurm コマンドが使用可能です。
$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
my-first-queue up infinite 5 idle~ node-group-1-[1-5]
$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
sbatchコマンドでジョブをサブミットすると、PCS コントローラ(マネージドなジョブスケジューラ)に以降のハンドリングを任せられます。
$ sbatch -p my-first-queue test.sh
Submitted batch job 1
$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
1 my-first- test.sh ec2-user CF 0:32 1 node-group-1-1
コンピュートノード(計算用の EC2 インスタンス)を自動起動して、指示した処理をコンピュートノード上で計算して結果を返してくれるという一般的なスパコンの利用方法と同じ流れになります。

料金体系
AWS PCS の料金には目新しい 2 つの課金要素があります。マネージドサービスになった分の費用はここの金額に反映されます。
- コントローラー料金
- ノード管理料金
両方とも1時間単位の従量課金制です。
この他には計算に使用した EC2 インスタンスの料金が発生します。ここは AWS ParallelCluster や、AWS Batch でも同じです。
コントローラー料金
PCS コントローラーの処理能力に応じて 3 つのサイズが提供されています。
| Slurm コントローラーサイズ | オーケストレーションされるインスタンス数 | アクティブおよびキュー内のジョブ数 | 月額利用費(東京) |
|---|---|---|---|
| Small | 1-32 | 1-256 | $554.5 |
| Medium | 32-512 | 256-8,192 | $3,101.5 |
| Large | 512-2,048 | 8,192-16,384 | $6,228.5 |
現在 PCS コントローラ停止できる設定は見当たらないため、この金額は月額の固定費だとお考えください。Large クラスの大規模クラスターの利用になると良いお値段しますね。
ノード管理料金
コンピュートノードグループで起動するインスタンスごとに 1 時間単位で課金されます。
- Advanced: P 系インスタンスタイプ、Trn 1 インスタンスタイプが該当
- Standard: それ以外のインスタンスタイプ
| Tier | 料金/時間 |
|---|---|
| Standard | $0.1058 |
| Advanced | $0.8462 |
東京リージョンの利用費です。
コンピュートノードを管理する代として別途課金されるのは、今までの HPC サービスにはない課金体系です。1 時間単位の課金されることから、1 分で終わるテストジョブを T 系インスタンスで実行させても、約 $0.1 の課金が発生するようです。
まとめ
AWS Batch ほどのフルマネージドサービスではなく、AWS ParallelCluster ほど律儀にインフラの面倒みなくても良い新しい HPC 向けのマネージドサービスです。
- 高可用性:マネージドなジョブスケジューラ提供により可用性が向上しました
- 運用負荷の軽減:インフラ管理、運用が減りました
- 使いやすさ:従来の HPC 環境と同様の操作感を維持したマネージドサービスです
おわりに
AWS PCS は従来の HPC 環境の使用感を維持しつつ、運用管理を簡素化しています。複雑なインフラ管理、運用から解放され、研究者や、エンジニアが本来の作業に集中できるのではないでしょうか。次回は AWS PCS のクラスターの構築方法は紹介しようかなと思います。









